Tile2Vec: Unsupervised representation learning for spatially distributed data
TL;DR: Highlights from our AAAI 2019 paper, “Tile2Vec: Unsupervised representation learning for spatially distributed data”. We extend the distributional hypothesis from NLP to spatial data and use it to learn representations of satellite imagery that can be used for different kinds of downstream tasks. We show that the features learned by Tile2Vec, without any labeled data, achieve performance comparable to fully supervised CNNs trained on 50k+ labeled examples on a difficult land cover classification task.

High-resolution satellite image of Emmingen-Liptingen, Germany from Google Earth.
What is remote sensing and why is it important?
Remote sensing is the measurement of the Earth’s surface through drone, aircraft, or satellite-based sensors. Besides providing gorgeous new perspectives of our planet, remotely collected data also gives us the power to continuously monitor global phenomena with increasing spatial and temporal resolution. Compelling use cases range from precision agriculture to tracking progress on the UN Sustainable Development Goals.
In recent years, commercial space companies such as SpaceX have reduced the cost of sending sensors into space by a factor of 20 (Jones 2018). Remote sensing now provides a nearly endless stream of data, containing all kinds of valuable information — the problem has shifted to making sense of it all.
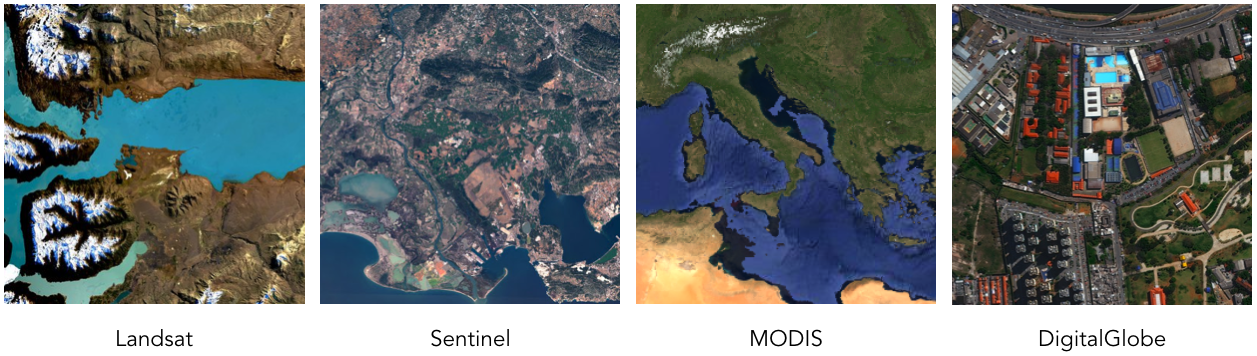
Example images from different satellites.
Learning to overcome data scarcity
Many of the success stories of deep learning have been enabled by large, painstakingly labeled datasets — ImageNet is the classic example. For many of the questions that we’d like to answer with satellite imagery though — measuring poverty in Africa, tracking deforestation in the Amazon — we care precisely because we are lacking in quality data!
One general approach to this problem is learning a lower-dimensional representation of the data that can be used for any number of downstream machine learning tasks. In computer vision, pre-training CNNs on ImageNet is a de facto standard for reducing the data requirements on a new task. Satellite images are taken from a bird’s eye view though, rendering this strategy ineffective. In the multispectral case, pre-training is not even possible — clearly these unique characteristics will require new methodologies.
The distributional hypothesis
The distributional hypothesis in linguistics is the idea that a word is characterized by the company it keeps. Alternatively, words that appear in similar contexts should have similar meanings: If you hear that “my neighbor’s tarpik keeps chasing my cat and barking at my car”, you’re probably thinking of an animal that looks like a dog even if you’ve never seen the word tarpik before.
In natural language processing (NLP), this assumption that meaning can be derived from context is leveraged to learn continuous word vector representations like Word2vec and GloVe (Mikolov et al. 2013) (Pennington, Socher, and Manning 2014). These word vectors can capture the nuanced meanings of huge vocabularies of words and have enabled huge advances on almost every core NLP task.
Context in spatial data
If you look at the satellite image tile below, you might have a guess as to which option is the missing piece.

Which is the missing piece?
The correct answer was C. Were you able to figure it out? If so, how?

Turns out fields are often surrounded by other fields.
We can see that a sort of distributional hypothesis like the one in NLP also exists for satellite imagery — context matters! Tobler’s First Law of Geography states:
Everything is related to everything else, but near things are more related than distant things.
This seemingly nonchalant observation will end up allowing us to learn powerful representations of spatial data.
The challenge
We want our representations to reflect what is actually on the Earth’s surface at that location. This goal is trickier than it seems — satellite tiles that look very similar to the eye may actually contain very different objects and environments.
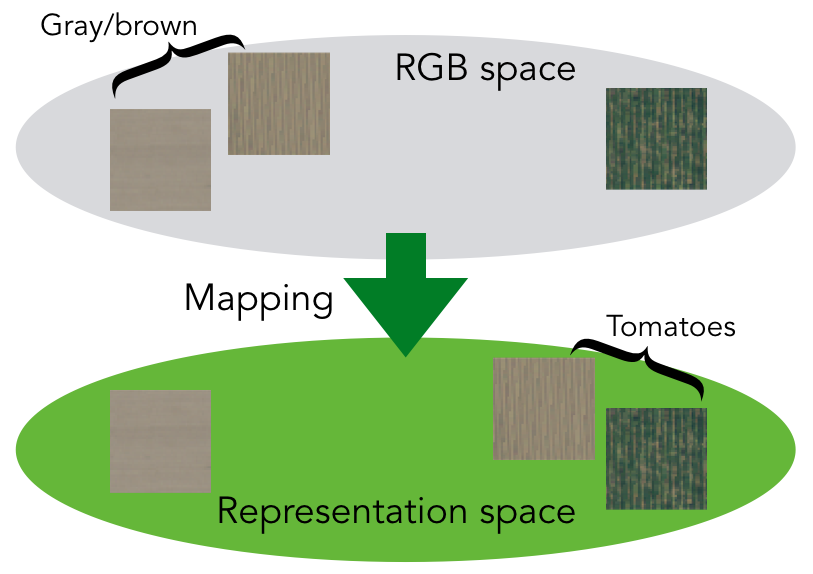
Things may not be as they appear.
In this example, we want our learned representation to know that the two tiles containing tomatoes should be similar even if they are not very close in the original RGB space.
Tile2Vec
To extend the Word2vec analogy from NLP, we take image tiles to be our “words” and spatial neighborhoods (defined by some radius) to define our context. To learn a mapping from image tiles to low-dimensional embeddings, we train a CNN on triplets of tiles, where each triplet consists of an anchor tile \(t_a\), a neighbor tile \(t_n\), and a distant tile \(t_d\).
We assume that tiles from the same neighborhood are more likely to be similar than their more distant counterparts. For a typical land-cover classification task, we see that anchor and neighbor tiles often come from the same class, while distant tiles are usually more dissimilar.

Each row contains a triplet, where the three columns on the right show the corresponding ground-truth land-cover class corresponding to the tiles in the three leftmost columns. Anchor and neighbor tiles usually contain similar things since they are closer together, while distant tiles (being distant) are more likely to be different.
For each triplet, we train the CNN to minimize the distance between the anchor and neighbor embeddings, while maximizing the distance between the anchor and distant embeddings:
\[L(t_a, t_n, t_d) = [ ||f_\theta(t_a) - f_\theta(t_n)||_2 - ||f_\theta(t_a) - f_\theta(t_d)||_2 + m]_+\]where we use the notation \([\cdot]_+\) to represent a rectifier, \(\max(0, \cdot)\) — we combine this with a margin \(m\) that puts a limit on how far the network can push the distant tile away to improve the loss. We use \(f_\theta\) to represent the mapping learned by the CNN, where \(\theta\) are the parameters that we are learning.
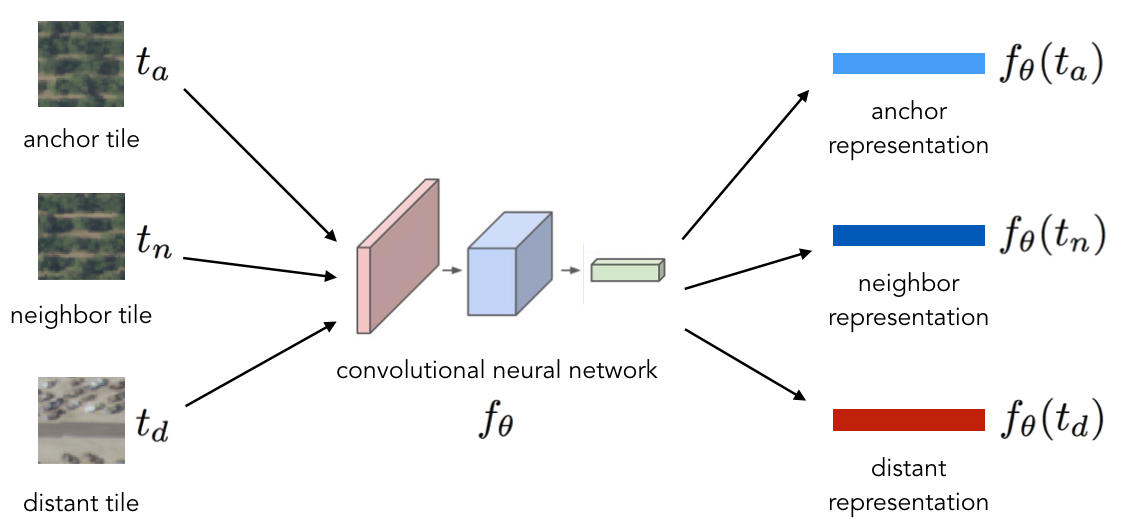
The same CNN is used to embed each tile in the triplet into a vector representation.
Exploring the learned representations
Can such a simple idea help us learn powerful and general representations?
It turns out that it can! When we compare the features learned by Tile2Vec to several supervised CNNs on a land-cover classification task, we find that the supervised models need at least 50k labeled examples to achieve the same level of performance.
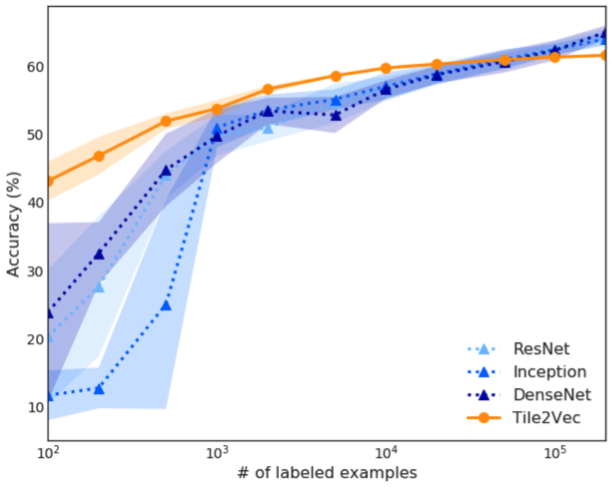
Supervised CNNs need around 50k labeled examples to match the performance of Tile2Vec unsupervised features.
We also evaluated learned features by exploring the latent space. By interpolating between the representations of two tiles in the dataset and finding the most similar tiles along the way, we can see whether the CNN learned concepts that are interpretable to a human.

Tile2Vec learns a semantically meaningful latent space. In this example, we can interpolate smoothly between farms and urban environments.
Discussion
Remote sensing provides a mostly untapped but highly promising source of data for monitoring both social and environmental phenomena. Tile2Vec demonstrates that with the right algorithms, we can turn simple bits of domain knowledge (neighboring places are usually similar) into powerful signals for unsupervised representation learning.
Tile2Vec: Unsupervised representation learning for spatially distributed data Neal Jean, Sherrie Wang, Anshul Samar, George Azzari, David Lobell, Stefano Ermon
AAAI Conference on Artificial Intelligence, 2019. paper code
References
- Jones, Harry. 2018. “The Recent Large Reduction in Space Launch Cost.” In . 48th International Conference on Environmental Systems.
- Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. “Efficient Estimation of Word Representations in Vector Space.” ArXiv Preprint ArXiv:1301.3781.
- Pennington, Jeffrey, Richard Socher, and Christopher Manning. 2014. “Glove: Global Vectors for Word Representation.” In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532–43.