Inference - satisfiability solvers
Brute force
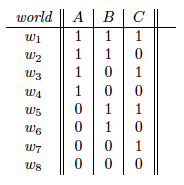
Figure from Chapter 3, page 1 of draft chapter on satisfiability by Adnan Darwiche
The brute force approach to checking satisfiability is to go through all possible worlds and check if the formula is satisfied. For example, a brute force approach for testing the satisfiability of some formula with three variables A, B, and C would visit the possible worlds in some order and check if the formula is satisfied in any of the eight worlds. To prove unsatisfiability, we would need to try all possible worlds. In the worst case, checking satisfiability is NP-complete because the number of possible worlds is exponential in the number of variables, and any kind of reasoning algorithm would take exponential time. Nonetheless, in practice, one can usually solve many kinds of real-world problems tractably using the techniques discussed below.
Early stopping
One improvement over brute force search is to do early stopping. We can visualize the search process as traversing a binary tree where each node corresponds to a variable and the left branch corresponds to setting that variable to true and the right branch corresponds to setting that variable to false. After making assignments to a couple of variables, we might be able to declare early success if we find a satisfying assignment. In addition, whenever we encounter a formula that is already unsatisfiable, we backtrack and avoid the need to search the subtree rooted at that node.
Note that this algorithm requires us to choose a variable ordering. Each time we go down a branch and make a variable assignment, we can simplify the CNF. At every step, we check if there exists an empty clause which means that the formula cannot be satisfied. If we eliminate all of the clauses, then the formula is satisfiable.
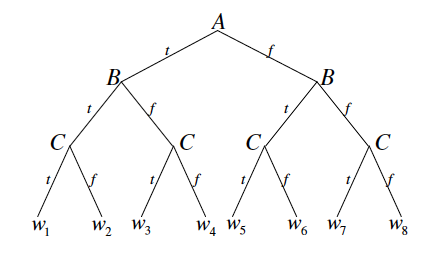
Figure from Chapter 3, page 2 of draft chapter on satisfiability by Adnan Darwiche
Going back to our earlier example with three variables A, B, and C, we traverse the tree starting from the root and check if the formula is satisfied or unsatisfiable each time we make an assignment to a variable. For the hypothetical formula , upon setting to true, we know that the formula becomes unsatisfiable, so we can immediately backtrack and set to false. Then when we set to true, we can immediately conclude that the formula is satisfiable.
Unit resolution
Whenever there is a clause with only one literal, then the only way to satisfy the formula is to set the corresponding variable so that clause is true. For example, if consists of , then we must set B to true, then set C to false, and finally D to false.
Another improvement is if a variable only appears in the formula in its negated or unnegated form, then we know how to set the value of that variable.
DPLL algorithm
The DPLL algorithm combines DFS with early stopping, unit propagation and pure literals. With these heuristics, DPLL is a very effective backtracking SAT solver. The recursive algorithm for DPLL is as follows.
:
- If is empty, return satisfiable.
- If contains an empty clause, return unsatisfiable.
- If contains a unit clause , return .
- If has a pure literal , return .
- Let be a literal from a minimum size clause of . If returns satisfiable, return satisfiable. Else, return .
Clause Learning
Fundamentally, the biggest limitation from a backtracking solver like DPLL is that you don’t learn from your mistakes so you might make the same mistakes over and over. For example, suppose that the variable ordering we choose for DPLL is unlucky in that the decision we make for the first variable leads the rest of the clauses to be inconsistent but unit propagation cannot detect this so we end up visiting each assignment to the variables that is not a satisfying assignment.
Clause learning adds clauses that are implied by the knowledge base, which are discovered during the search process, to the knowledge base. Adding clauses that are implied by the knowledge base, particularly short clauses, can empower unit propagation and allow a different way of searching the tree that is non-chronological.
We will use a graph-based data structure, called an implication graph, that has nodes corresponding to variable assignments (either decisions we make when branching or implications via unit propagation). The directed edges in the graph will record dependencies among the variable assignments. Each node in the implication graph has the form which means that at level , variable has been set to value . Whenever we branch on a variable, we create a node for this variable assignment but do not add any edges. Whenever unit propagation allows us to derive the value of a variable, we create a node for this variable assignment, and we add directed edges to this new node from the nodes corresponding to the variable settings that allowed unit propagation to make this derivation and label each edge with the clause that was used to make the derivation.
When we reach a contradiction, we can build a conflict graph and identify opportunities to learn from mistakes. In an implication graph which terminates in a contradiction, every cut that separates the decision variables from the contradiction defines a conflict set. The nodes in the conflict set are exactly the source nodes of all of the (directed) edges that cross the cut.
Though there may be several conflict sets, a typical approach is to identify a cut so that there is only one decision variable at the highest (last) decision level on the reason side and then backtrack to the second highest (second to last) decision level. Following this backtracking procedure, the clause that was added is guaranteed to trigger unit propagation.
Another approach is to identify a Unique Implication Point (UIP) which is a node at the highest decision level that appears in every path from the highest decision level to the contradiction. If there is more than one UIP, often we choose a UIP that is closest to the contradiction since this might allow shorter clauses.
Non-chronological backtracking is sound and complete assuming we keep all of the clauses that we learned. Note that non-chronological backtracking might go down the same path multiple times.
Example for DPLL and Clause Learning
Consider the formula below:
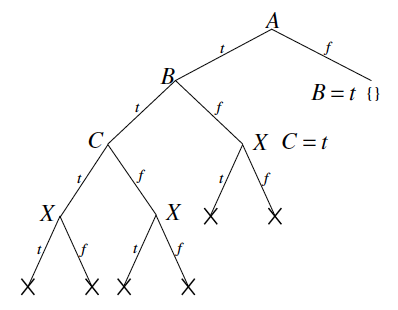
Figure from Chapter 3, page 8 of draft chapter on satisfiability by Adnan Darwiche
For DPLL, assume the variable ordering for the search procedure and that variables are assigned true before being assigned false when branching. The result of running DPLL on this formula is given by the figure above. We see that the DPLL algorithm is forced to explore almost half of the entire tree before it is able to detect the contradiction.
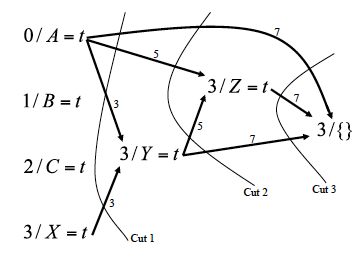
Figure from Chapter 3, page 11 of draft chapter on satisfiability by Adnan Darwiche
On the other hand, when running CDCL on the same formula with the same search tree, CDCL will learn a good clause to add to the KB from a cut in the implication graph. These learned clauses allow CDCL to traverse the search tree in a more efficient manner.
Engineering considerations
Key features of SAT solvers:
- Conflict-driven clause learning
- Unit propagation with watched literals
- Dynamic variable selection/branching heuristic
- Random restarts
An efficient implementation of unit propagation is very important since a lot of time is spent doing unit propagation. We can implement unit propagation more efficiently by using a lazy approach. We only watch two variables in each clause. Every time we assign a variable, we only need to check the clauses for which that variable is watched. Whenever a watched variable becomes assigned to true or false, we check each clause for which that variable is watched: if we can we do unit propagation, we do unit propagation and that clause becomes satisfied; otherwise, we find another variable in that clause to watch.
In what order do we assign the variables and values? We try to keep track of how important each variable is. One heuristic is that if a variable appears in many clauses, it’s probably more important.
Restarts with different random seeds (while keeping learned clauses) can be very helpful in practice because the runtime distribution of backtrack search methods exhibits a heavy tail. The size of the search tree can vary dramatically, depending on the order in which we pick the variables, so a SAT solver can get lost in a large part of the state space where there is no solution. If you keep doing restarts, how can you guarantee completeness? One heuristic is to double the restart cutoff each time.
Tutorial on practical SAT solvers
MiniSat is a “minimalistic, open-source SAT
solver, developed to help researchers and developers alike to get
started on SAT.” MiniSat can be installed from their Github
repository. Mac users can install
MiniSat directly using Homebrew with the command
brew install minisat. MiniSat usage is
minisat [options] <input-cnf-file> <result-output-file> where options
can be viewed with minisat –help.
Examples of benchmark problems are available
here. For example, we
can download
CBS_k3_n100_m403_b10
random 3-SAT instances which have 100 variables, 403 clauses, backbone
size 10 - 1000 instances, all satisfiable. After unzipping the file, we
can solve one of the instances using MiniSat with the command
minisat CBS_k3_n100_m403_b10_0.cnf. By viewing this file in a text
editor, we see that the first 3 lines are comments (lines starting with
“c”), the next line is the problem header p cnf 100 403 representing
p FORMAT NUM_VARIABLES NUM_CLAUSES, and each subsequent line
represents a clause where the variables in the disjunction are listed
(negated variables appear with a negative sign and each line is
terminated with a “0”). Variables are assumed to be numbered from 1 to
n. For example, the clause
is represented as
-9 40 -68 0. Further descriptions of the file formats are available
here.