Inference - random walk satisfiability solvers
Introduction
So far, we’ve introduced propositional logic and considered the problem of deciding whether a propositional formula is satisfiable. The algorithms we’ve studied so far to decide satisfiability, such as DPLL and CDCL, are algorithms which conduct a systematic search of the state space, terminating only when the algorithm has found a satisfying assignment or a proof that the formula is unsatisfiable.
In this lecture, we’ll introduce a randomized algorithm for deciding whether a propositional formula is satisfiable or not, which returns a correct answer with high probability. Instead of systematically searching the state space, we’ll conduct a random walk over the state space which can then be analyzed using Markov chains.
The setup for the random walk is as follows. Given a formula with Boolean variables, define our state space to consist of all possible truth assignments to these Boolean variables. By considering a mapping from truth assignments to binary strings of length , our state space can be equivalently viewed as a Boolean hypercube of dimension , where each of the vertices corresponds to a truth assignment. Later, we will set up a randomized search procedure which does a random walk over the possible states to decide whether a formula is satisfiable. This type of search is known as a stochastic local search procedure.
Review of Markov chains
A Markov chain is a discrete stochastic process where each ( is the state space). A Markov chain satisfies the Markov property, the key conditional independence relationship: the future is conditionally independent of the past given the present. Explicitly, we can write this as for all possible states and all time steps .
Furthermore, if holds for all , then the transition probabilities are independent of time, and we call the Markov chain homogenous. In this case, we can define the transition matrix , and the full joint probability distribution defined by the Markov chain is then completely determined by the transition matrix and the initial probability distribution .
Graphically, we can represent a Markov chain as a directed graph with weighted edges. Each node in the graph represents a possible state of the Markov chain. We have directed edges between nodes with edges weights representing the probability of transitioning between the corresponding states.
Random walk algorithm for 2-SAT
Let the state space be the set of vertices of the Boolean hypercube. Since the number of possible states is , for large , the state space cannot be enumerated completely, and the transition matrix cannot be represented explicitly. We want to find a way to simulate from the Markov chain without representing the Markov chain explicitly.
We’ll first consider the following algorithm for solving 2-CNF formulas (a CNF formula where every clause has at most 2 variables) and then generalize later.
Input: a 2-CNF formula with variables
- Repeat times:
- Pick an arbitrary truth assignment
- Repeat times:
- If satisfies all clauses, return satisfiable
- Otherwise, pick any clause that is not satisfied and choose one of the variables uniformly at random from this clause and flip the truth assignment of that variable
- Return unsatisfiable
Analysis of algorithm for 2-SAT
If the propositional formula is unsatisfiable, then the algorithm will always return unsatisfiable. If the formula is satisfiable, then the algorithm might not find the satisfying assignment. This is the only case where the algorithm makes a mistake. We’ll bound the error probability for this case.
Let be a truth value assignment which satisfies the CNF formula. Let be the truth assignment in the iteration of the inner loop. Define the random variable to be the number of bits for which and match. If , then we’ve found the satisfying assignment .
Note that when we flip any one bit in , either increases or decreases by 1. Thus, in the inner loop when we flip the truth assignment of some variable, if , then can only take on the values .
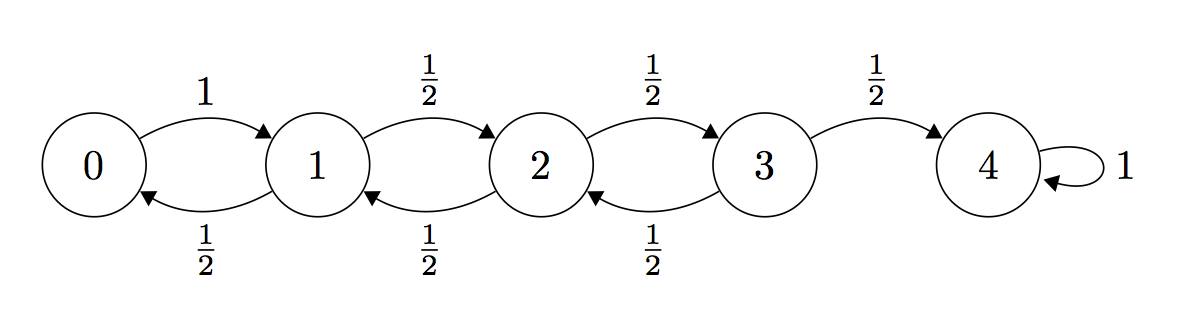
To analyze the transition probabilities, note that when we pick a violated clause in the inner loop, we know that the truth assignment for at least one of the variables in that clause does not match the corresponding truth assignment in (because is a satisfying assignment). In either the case where one of the variables is set incorrectly or both of the variables are set incorrectly, the following inequalities hold for the transition probabilities:
for any and all time steps . For the boundary cases, we have that and for all .
Thus, we see that the random walk algorithm defines a stochastic process with a Markov chain over the random variable , where each . For the purposes of our analysis, we will treat the transition probabilities as exactly which give us a bound on the worst-case performance.
Define # of steps to reach state from state , and define . Note that the variables take on the boundary values and . The expected number of steps are related via the formula:
Claim 1:
Proof: Define . From the recurrence relation above, we have that . Since by the boundary condition, it follows that .
Claim 2:
Proof: Since by the boundary condition, it follows from repeated application of Claim 1 that .
Thus, we see that if the formula is satisfiable, the random walk will take, in expectation, roughly steps to find the satisfying assignment . Let number of steps the random walk takes before reaching state . By Markov’s inequality, , so the probability that the random walk does not find the satisfying assignment in steps is . By running many independent runs of this algorithm, the failure probability for this random walk algorithm can be lowered to at most . Thus, we see that this random walk algorithm provably solves 2-SAT in polynomial time.
Random walk algorithm for 3-SAT
Last lecture, we described and analyzed a random walk algorithm for deciding whether or not a 2-CNF formula is satisfiable. Now consider running the same algorithm presented last time on a 3-CNF formula. We’ll see later on in this lecture why we choose to repeat the inner loop times and always generate our truth assignment uniformly at random.
Input: a 3-CNF formula
- Repeat times:
- Select truth assignment uniformly at random
- Repeat times:
- If satisfies all clauses in , return satisfiable
- Otherwise, pick any clause that is not satisfied and choose one of the variables uniformly at random from this clause and flip the truth assignment of that variable
- Return unsatisfiable
Analysis of algorithm for 3-SAT
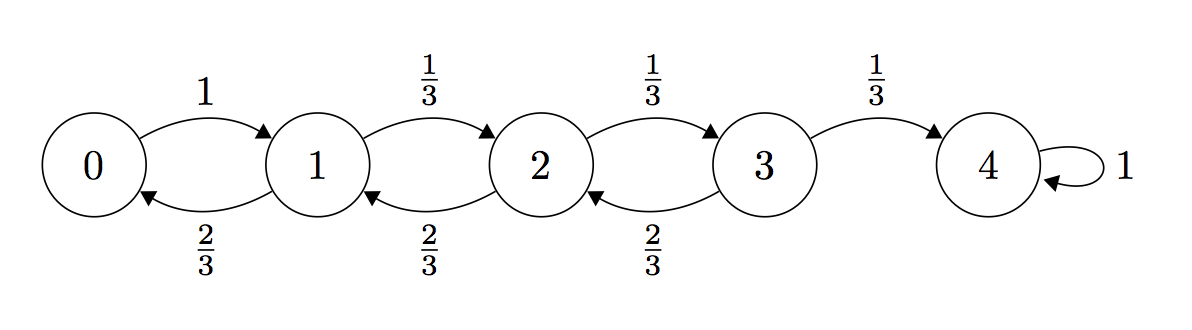
Using a similar analysis as in the last lecture, the bounds for the transition probabilities become
for any and all time steps . For the boundary cases, we have that and for all .
Define # of steps to reach state from state , and define . Note that the variables take on the boundary values and . The expected number of steps are related via the formula:
Define . From the recurrence relation above, we have that . Since by the boundary condition, . Therefore, , and this gives us a biased random walk where .
If we work out the terms explicitly, we have that . Note that even . This means that even if we were only one state away from finding the satisfying assignment, the expected running time is still exponential. This observation motivates the following modification to our algorithm.
Suppose that we have a way of starting the Markov chain at state . Then instead of simulating the Markov chain for an exponential number of steps hoping to find the satisfying assignment, the best approach is to continually restart the Markov chain at state and just take 1 step at a time until we find the satisfying assignment. We will extend this idea to our algorithm by using very aggressive random restarts and short random walks.
To start, recall that our algorithm will select a truth assignment uniformly at random. The probability that our initial assignment will have of the truth assignments assigned correctly is .
Consider a short sequence of moves and let us compute the probability that if we make moves, we have moves to the left and moves to the right: .
Now suppose we start at state . Let us work out a lower bound for , the probability of reaching state , starting at state , in moves. In particular, probability that if we make moves, we have moves to the left and moves to the right. Using the formula above, we have that .
By Stirling’s approximation, so
for . Combining this bound with our previous expression, for . The boundary condition is .
Combining everything, the probability that we will reach state , starting from a truth assignment initialized uniformly at random, in moves is
Therefore, the expected number of times that we have to repeat the procedure before getting a success is . Choose . Then our algorithm succeeds with probability at least with running time . We can finally boost our algorithm to the desired success probability. In conclusion, we’ve seen that we can go from a biased random walk with to an expected run time of by using very aggressive random restarts.
Other variants
WalkSAT
WalkSAT is similar to the random walk algorithm described above. The difference is that when trying to fix a violated clause, WalkSAT will be greedy with some probability.
After selecting a clause ,
- With probability , pick a variable in at random and flip the truth assignment of
- Otherwise, go through all the variables in and choose the variable with the smallest break count to flip (number of satisfied clauses that become unsatisfied when the variable is flipped).
GSAT
- With probability , choose a variable at random and flip the truth assignment
- Otherwise, check all variables and select the variable with largest make count - break count
Simulated annealing
- Randomly pick a variable, calculate make count - break count
- If the new state is a better state (lower energy), always make the transition
- Otherwise, accept the transition with probability where T is the temperature parameter
Note that the randomness helps the algorithm not get trapped in local minima.